
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 정보시스템설계및분석
- 자연어처리
- 메타휴리스틱
- 지식재산경영
- 이공계를위한특허이해
- 산업공학
- 공대생의전공공부
- 고전방법론
- 최적화문제
- 컴퓨터공학
- 지적재산권
- 통계학
- 언어학
- 공대생의문과공부
- 경제용어
- 공대생의경제공부
- 일일경제공부
- 특허
- 공대생의연구공부
- 품질경영
- 국어국문학
- 정보시스템
- 확률기반자연어처리
- 공대생의언어학공부
- 공대생의산업공학공부
- 인공지능
- 영어영문학
- 통계적품질관리
- 최적화기법
- 언어적지식
- Today
- Total
Fintecuriosity
[메타 휴리스틱] 벌금 전략(penalizing strategy) 본문
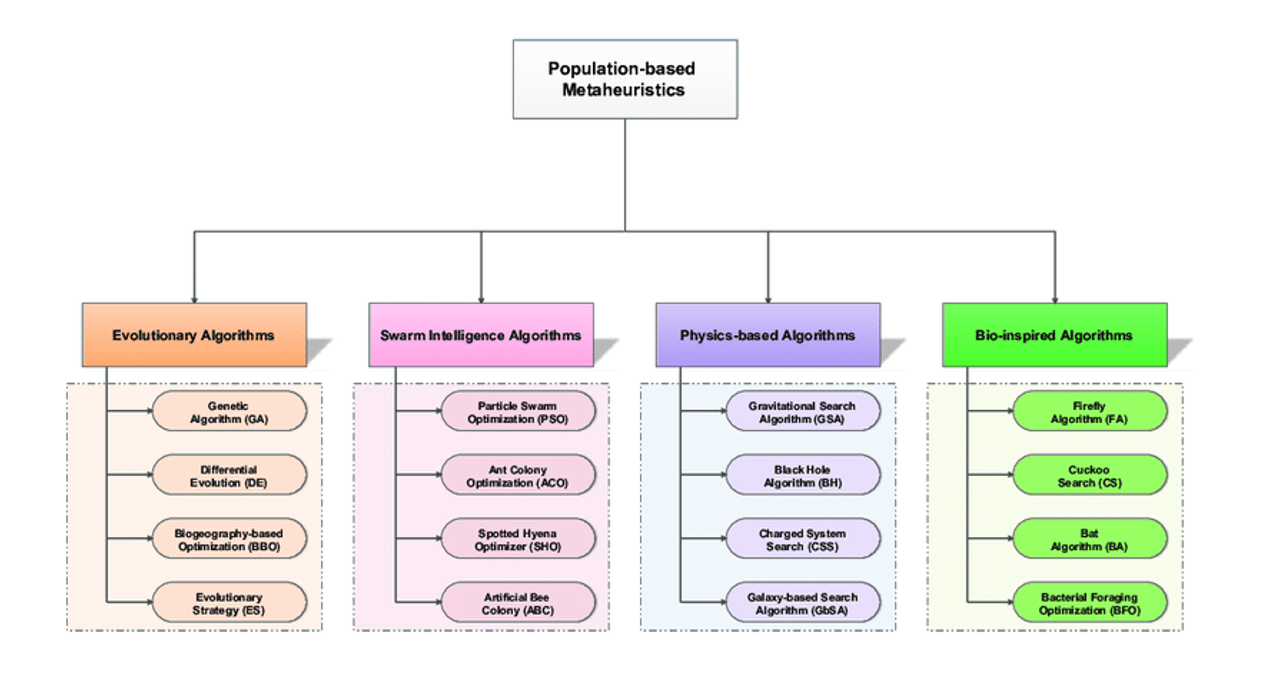
이번 글의 내용은 전남대학교 산업공학과 김여근 교수님의 메타휴리스틱 교재 정리 및 참조하였음을 먼저 밝힙니다.
(다른 참조한 논문과 자료들은 아래에 기재되어 있습니다.)
이 포스트는 "메타 휴리스틱" 책의 내용을 참조 및 공부한 것을 바탕으로 제가 이해한 정보를 추가하여 쓰여졌습니다.
혹시 제가 잘못 알고 있는 점이나 보완할 점 있다면 댓글로 알려주시면 감사하겠습니다.
※ 비가능해이면 평가값에 벌금을 주는 벌금 전략은 메타휴리스틱에서 가장 널리 사용되는 전략입니다.
이 전략은 비가능 영역으로의 이동을 허용하고 비가능해를 후보해로 받아들이는 탐색전략입니다. 이러한 탐색 전략은 제약이 강한 문제에서 효과적일 수도 있고, 단일해 기반 보다는 집단 기반 메타휴리스틱스에서 더욱 효과적으로 구현할 수 있습니다.
흔히 벌금은 제약조건을 어기는 정도에 부과합니다. 이때 비가능해의 평가값은 가능해 보는 더 좋지 않도록 부과합니다. 이 전략은 제약 최적화 문제에서 비교적 쉽게 사용할 수 잇는 효과적인 방법입니다.
긴글 읽어주셔서 감사합니다.
[References]
[1] Y. Kim. (2017). 메타휴리스틱스, Metaheuristics
[2] Nanda, S. J., & Panda, G. (2014). A survey on nature inspired metaheuristic algorithms for partitional clustering. Swarm and Evolutionary Computation, 16, 1–18.
'Industrial Engineering > 메타휴리스틱' 카테고리의 다른 글
| [메타 휴리스틱] 해독 전략(decoding strategy) (0) | 2020.10.04 |
|---|---|
| [메타 휴리스틱] 보수 전략(repairing strategy) (0) | 2020.10.02 |
| [메타 휴리스틱] 비가능해 버리기 전략(reject strategy) (0) | 2020.09.30 |
| [메타 휴리스틱] 집단 기반 메타휴리스틱스 (0) | 2020.09.30 |
| [메타 휴리스틱] 단일해 기반 메타휴리스틱스 (0) | 2020.09.30 |



