
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 일일경제공부
- 언어학
- 특허
- 영어영문학
- 자연어처리
- 최적화문제
- 통계적품질관리
- 컴퓨터공학
- 메타휴리스틱
- 지적재산권
- 국어국문학
- 인공지능
- 공대생의문과공부
- 품질경영
- 경제용어
- 고전방법론
- 이공계를위한특허이해
- 산업공학
- 공대생의언어학공부
- 공대생의경제공부
- 언어적지식
- 지식재산경영
- 통계학
- 공대생의연구공부
- 정보시스템설계및분석
- 공대생의전공공부
- 정보시스템
- 공대생의산업공학공부
- 확률기반자연어처리
- 최적화기법
- Today
- Total
Fintecuriosity
[자연어 처리] 시소러스 (thesaurus) 본문

이번 글의 내용은 고려대학교 컴퓨터공학과 이상근 교수님의 "뉴럴 모델을 이용한 자연어 처리" 저서를 참조 하였음을 먼저 밝힙니다. (다른 참조한 논문과 자료들은 아래에 기재되어 있습니다.)
혹시 제가 잘못 알고 있는 점이나 보완할 점 있다면 댓글로 알려주시면 감사하겠습니다.
NLP 분야에서는 오래 전부터 컴퓨터에 인간의 언어를 이해시키는 방법을 연구했습니다. 인간의 언어를 자연스럽게 이해할 수 있는 컴퓨터가 있다면 인간이 할 수 있는 수많은 일을 컴퓨터가 수행할 수 있을 것이라고 판단하였습니다.

가장 쉬운 방법으로, "인간의 언어 사전을 그대로 컴퓨터에 넣어서 활용해 보자!"는 아이디어를 떠올릴 수 있습니다. 학자들은 이 아이디어를 조금 더 발전시켜서, 인간의 단어 중 동의어와 유의어의 관계, 상/하위 관계를 정의한 사전을 만들어내고, 이를 시소러스(thesaurus)라고 명명하였습니다.
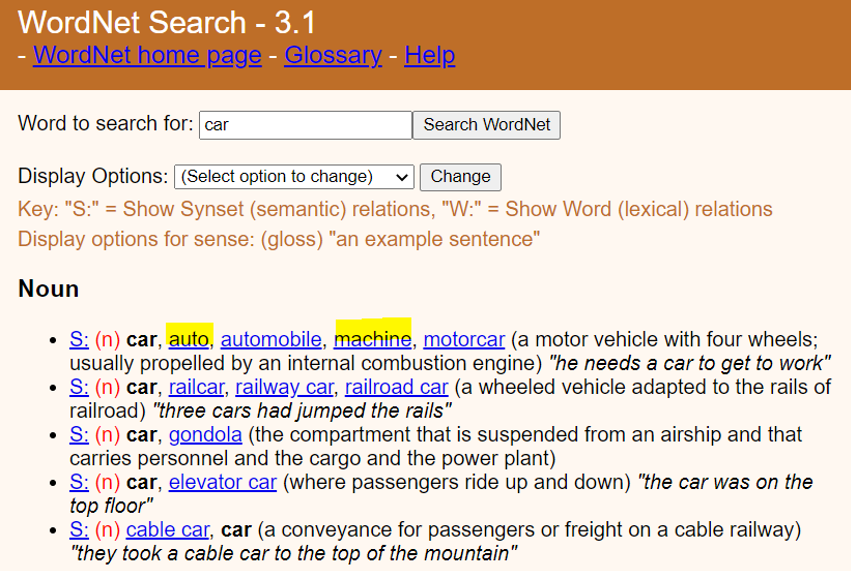
가장 대표적인 시소러스는 1985년에 제안된 WordNet이 있습니다. 현재는 약 1억 개의 동의어 집합(synset)을 보유하고 있으며, 이를 통하여 단어 사이의 유사도를 구하거나 상하 관계를 얻어 낼 수 있습니다. 그러나 이러한 시소러스를 사용하는 방법에는 몇 가지 문제점 또한 존재하고 있습니다.
첫째, 시소러스의 구축은 온전히 사람이 진행해야 하는데 이에 따른 비용이 크게 발생합니다.
둘째, 언어는 시대에 따라 많은 표현이 생기고 사라지는데 이러한 현상에 직각,실시간으로 대응하기 어렵습니다.
마지막으로, 뜻이 비슷하지만 미묘한 단어들의 차이를 구분해 내기 힘듭니다.
※ 예를 들면 시소러스는 "auto"와 "machine"을 같은 의미로 인식하는 것을 확인할 수 있었습니다.
이러한 어려운 문제들 때문에 현재에는 사람이 직접 관계를 만들던 방식에서 탈피하여 컴퓨터가 스스로 관계를 찾아내게끔 하는 방식으로 변하고 있습니다.
긴 글 읽어주셔서 감사합니다.
References
[1] S. Lee. (2020). 뉴럴 모델을 이용한 자연어 처리.
'Artificial Intelligence > 자연어 처리' 카테고리의 다른 글
| [자연어 처리] 자연어 처리 학문 (0) | 2020.07.31 |
|---|---|
| [자연어 처리] 자연어 처리란 무엇인가? (0) | 2020.07.31 |

